
About Hadoop BigData Training
Hadoop is a framework which is designed to solve the problems related to Big Data. Each and everyday numerous amount of raw data is generated from different kinds of sources, this data contains lot of useful information which help solve many different kinds of problems. Hadoop helps in analysis of this huge data and provides with useful information.
HADOOP BIGDATA HIGHLIGHTS
BIGDATA COURSE OUTCOME

WHO WILL BENEFIT
HADOOP BIGDATA COURSE CURRICULUM
Introduction
Why Learn Big Data?
Why Learn Big Data?
 90% of the data in the world today is less than 2 year old.
90% of the data in the world today is less than 2 year old.
- 18 Moths is the estimated time for digital universe to double.
- 2.6 Quintillion bytes is produced every day.
- Definition with Real Time Examples
- How BigData is generated with Real Time Generation
- Use of BigData-How Industry is utilizing BigData
- Future of BigData!!!
Module 1: BigData
- Why Hadoop?
- What is Hadoop?
- Hadoopvs RDBMS, HadoopvsBigData
- Brief history of Hadoop
- Problems with traditional large-scale systems
- Requirements for a new approach
- Anatomy of a Hadoop cluster
Module 2: Hadoop
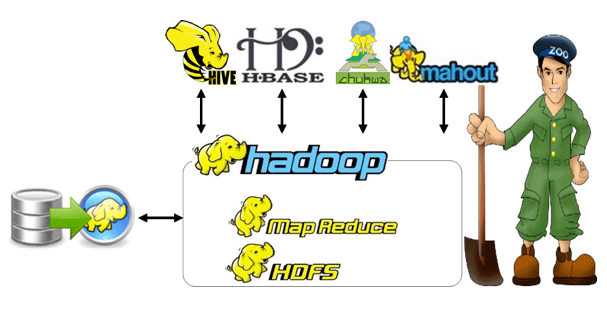
Module 3: HDFS
- Concepts & Architecture
- Data Flow (File Read , File Write)
- Fault Tolerance
- Shell Commands
- Java Base API
- Data Flow Archives
- Coherency
- Data Integrity
- Role of Secondary NameNode
Module 4: MapReduce
- Theory
- Data Flow (Map – Shuffle - Reduce)
- MapRedvsMapReduce APIs
- Programming [ Mapper, Reducer, Combiner, Partitioner ]
Module 5: HIVE & PIG
- Architecture
- Installation
- Configuration
- Hive vs RDBMS
- Tables
- DDL & DML
- Partitioning & Bucketing
- Hive Web Interface
- Why Pig
- Use case of Pig
- Pig Components
- Data Model
- Pig Latin
Module 6: HBase
- RDBMS VsNoSQL
- HBase Introduction
- HBase Components Scanner
- Filter Hbase POC
Module 7:
Introduction to MongoDB
